Unleashing some creativity: one idea at a time
-
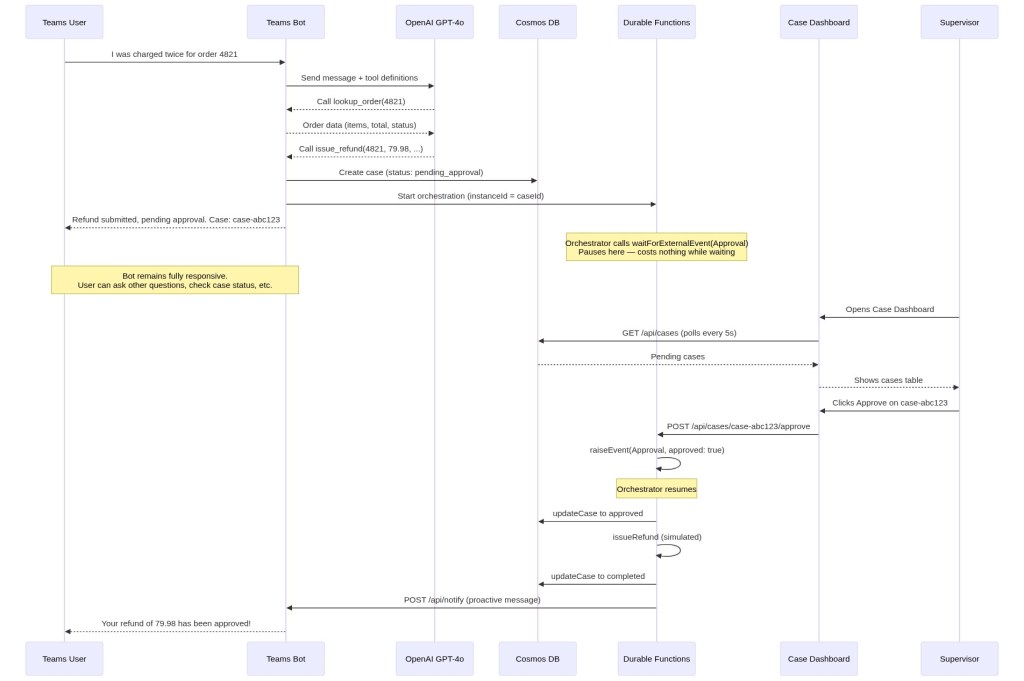
Stop Building State Machines for Your AI Agents (use Durable Functions instead)
I built a sample that I think captures something important: AI agents that interact with the real world need workflows that pause, and Durable Functions make this much easier than current alternatives. The Problem Say you’re building a support agent. A customer asks for a refund. The agent can look up the order, check the return policy, and…
-

Giving OpenClaw Its Own Identity, And a Sandbox to Run In
OpenClaw is an open-source AI agent framework that gives LLMs real tools and autonomy. It already has a built-in Teams channel, but it works as a traditional bot using delegated auth, meaning the agent acts with your permissions. OpenClaw A365 takes a different approach. Instead of a bot wearing your credentials, it gives the agent…
-

GoodDocs
Many of the docs we write exist to help teams make better decisions by writing down the thinking and reviewing it with others. With AI, it is easier than ever to generate a doc from a few words of a prompt, but when a draft looks “done” too quickly, important context and key aspects can…
-

Controlling AI Agent Participation in Group Conversations (Koala)
Last Friday, we had the opportunity to hear from Justin Weisz, Stephanie Houde, Steven Ross, and the IBM team about their research on controlling AI agent participation in group conversations. They ran a set of studies with a Slack bot called Koala to understand how an agent should behave in live multiparty brainstorming sessions. Read…
-
Inner Thoughts – Notes
We had the opportunity to host Bruce Liu, one of the authors of the Inner Thoughts paper, in our team’s AI learning session today. Sharing my key takeaways. Key Takeaways
-
MUCA – Notes
In today’s AI Learning session, we had the opportunity to meet Manqing Mao and Jianzhe Lin who co-authored MUCA. Capturing my notes here. There are several interesting ideas in the paper that are applicable to multi-human <-> agent collaboration. Multi-User Chat Assistant (MUCA): Framework for LLM-Mediated Group Conversations MUCA targets multi-user, single-agent interactions — a…
-

Embeddings & Similarity Metrics
When asked what embedding model and similarity metric they’ve used, most people answer something like: “OpenAI embeddings with cosine similarity.” That’s a perfectly valid answer. But it leads to deeper questions: These were some of the questions we dug into in our team learning session last Friday. Let’s walk through the key takeaways. First: the…
-

Context Rot
Last Friday, our learning session covered Context Rot, a paper from the Chroma vector database team on how longer inputs affect LLM performance. They ran experiments with 18 leading LLMs, like o3, GPT-4.1, Claude, Gemini, and Qwen, on needle-in-a-haystack style questions, then measured how often the models gave the right answer. The best way to…
-

Defining “AGI”
This week, one of the papers we discussed in my team was, the spicely titled, “What The F*ck Is Artificial General Intelligence?” by Michael Timothy Bennett, which I found after hearing him on MLST (still one of my favorite podcasts, has super high signal/noise). Several interesting points came up:
-

MCP Universe
Salesforce AI’s new MCP-Universe benchmark puts frontier models through 200+ real-world tool-use tasks. The results: GPT-5 lands at 43.7%, Grok-4 at 33.3%, and Claude-Sonnet at 29.4%. The rest of this post breaks down why these numbers are so much lower than BFCL, what domains drag models down most, and what the findings mean for teams…
Got any book recommendations?
